|
|
5. Query results
This section provides guidance on working with EANC query results:
5.1. Producing query results
5.2. Reading query results
5.3. Empty results
5.4. Computationally complex queries
5.5. Navigating query results
5.6. Expanding a match
5.7. Lexical morphological analysis
5.8. Sorting
5.9. Display characters
5.10. Output format
5.1. Producing query results
Once you click the Search or the QuickSearch button, the EANC search engine starts retrieving matches to your query. An estimate of the remaining search time is displayed (if the query consists of multiple tokens, the estimate will be updated for each subsequent token). If the query is complex and will take a long time to complete, you can interrupt the search by pressing Cancel.
Some queries may not return any results. In that case, a message will appear indicating possible reasons for this (a lexeme of a wordform in the query does not appear in EANC; selected gram features do not co-occur; etc. - see Empty results for further details).
If you click the Search in new window link, a new EANC window opens. The new window can be used for making independent queries or building a separate subcorpus. This may be convenient, for example, if you want to compare query results for two similar but not identical queries (e.g. searching for a particular grammatical construction in the 19th vs. the 20th century, etc.; see query example).
5.2. Reading query results
The top of the output screen lists the following information:
- number of matches; in cases where the number of matches approaches or exceeds 10,000, an estimate of the total number of matches and of the number of documents containing those matches
- selected sorting criteria (if any)
- subcorpus size as a percentage of the total number of tokens as well as the total number of sentences and of documents in the subcorpus (if a subcorpus has been specified)

Many queries correspond to more than 10,000 matches. However, only up to 10,000 matches are displayed to the user. These 10,000 are drawn from various parts of the Corpus proportionally to the way all matches are distributed throughout EANC, so as to form a representative sample (if a subcorpus has been defined, the same distribution sampling is performed over the subcorpus).
5.3. Empty results
Occasionally, a query may not return any results. In that case, a message will appear indicating possible reasons for this.
If the message says that a token or a token feature does not occur in the corpus, try to check the spelling of the form in the token query line. If you were looking for a lexeme, it is possible that this lexeme is not yet included in the EANC grammatical wordlist. After checking the spelling, try to query the token under the Wordform tab (use * to cover several wordforms). If this token does occur in the corpus, it will be found as a wordform.
If the same message appears after a gram query that does not specify a wordform or a lexeme, the reason might be that the combination of the specified categories (together with additional search criteria that may have been specified under the Advanced tab) do not co-occur in any one token. Check for logical compatibility of the grammatical categories in the gram query line; then review any advanced search criteria you may have entered and make them less specific. If you have typed the gram query directly into the gram query line, the same message will be displayed if you mistyped a grammatical label or made an error in the expression syntax (for example, “sing” instead of “sg” or “coverb” instead of “converb” or “N&loc” instead of “N, loc” etc.). For the correct syntax of gram queries see the Gram & Attributes Query section; for the list of gram labels used in EANC see Annotation. You can use the Gram Selection window which generates logical expressions for gram queries automatically.
You may also get a message indicating that the token and the feature(s) specified in the grammar query line (including advanced search options, such as punctuation or capitalization) do not co-occur in the corpus, even though they can be found separately.
Finally, for context queries, the message may say that the tokens do not co-occur in the same context, which means that each of the tokens occurs in the corpus separately, but no contexts are found in which they co-occur - or at least not within the distance range specified by the user.
5.4. Computationally complex queries
Some queries may lead to long computation times. For single token queries, the reason may be that the query is not specific enough. Common cases are:
- using a wildcard (*) in the token query line while specifying only one or two characters (e.g. all words ending in *ան *an )
- using the negation sign ~ in the token query line or in the gram query line without specifying any positive search criterion, so that a large number of matches is produced (e.g. ~մարդ * mard or ~V)
- querying for a common gram label without adding other grams (e.g. nouns “N” in any form)
Importantly, any context search which includes a computationally complex token query will necessarily take a long time to be processed, independently of how specific the whole query is. As an example, a search for խմել xmel immediately followed by մոտ mot will quickly compute its output, which contains very few matches. However, if you click on the Plus icon and specify that the word following մոտ mot must be a noun, the query will take a long time to complete.
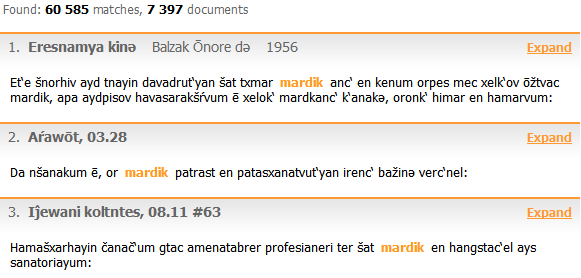
5.5. Navigating query results
Click on the First, Last or page number links at the bottom of the output screen to navigate through pages. The default number of matches per output page is 10; you can change this number by choosing the corresponding option in the Display Options window.
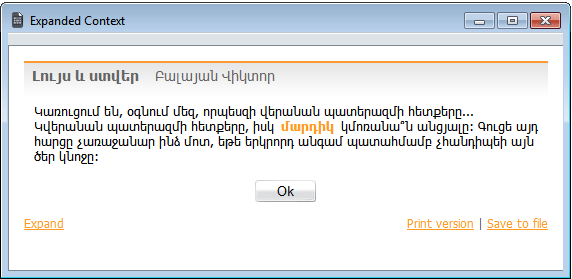
5.6. Expanding a match
By default, query search results are returned as single sentences with matching tokens highlighted in orange. Note that only one match per sentence is highlighted; if a sentence contains several matches, it may appear in the output multiple times, with different tokens highlighted each time.
Sentences containing query matches are displayed along with basic metatext information: author, title, and year/period of creation, if available. You can also open a window displaying sentences immediately following and preceding the one listed in the results by clicking Expand. The default number of sentences is 1 before and 1 after the match, and can be changed to 2 or 3 by choosing the corresponding option in the Display Options window. If you click Expand in the pop-up window, the displayed context will be further expanded to up to 4 sentences preceding and 4 sentences following the match. Further (unlimited) expansion is only possible for texts not protected by copyright - including works by authors who died more than 70 years ago, old press from before 1920, and oral texts.
5.7. Lexical morphological analysis
Moving the mouse over a wordform in the output screen opens a pop-up window showing the lexical morphological analysis of the wordform, followed by one or more English equivalents (when available). You can turn the pop-up window functionality on and off by choosing the relevant option in the Display Options window.

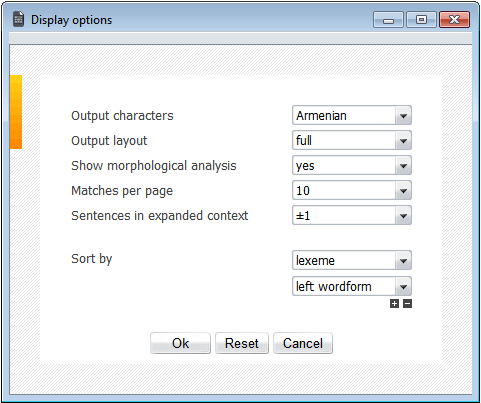
5.8. Sorting
EANC allows sorting the results by:
- matching lexeme
- matching wordform
- wordform to the left of the match
- author
- title
- year of creation (ascending or descending)
- genre
You can choose the sorting criteria in the Sort by field in Display Options window. You may sort the query result by several criteria, e.g. sorting a grammatical attribute query first by the lexeme, than by its specific wordform. To add/remove sorting criteria, click the Plus or Minus icons under the Sort by field.
5.9. Display characters
In case Armenian characters do not appear properly in the query results, you can switch to English transliteration by setting the Output Characters field in the Display Options window to "transliteration". EANC's transliteration rules mostly follow Huebschmann-Meillet conventions. Transliteration applies to all elements of the output, including authors and book titles.
5.10. Output format
EANC supports four output format types:
- Full (default style). Each sentence in the output is supplemented by basic metatext information: author, title, and year of creation.
- Light. No metatext information is provided. To get metatext data for a specific context, click Expand.
- Glossed. This layout is provided for typologists and other linguists who do not know Armenian and is very close to classical interlinear morphological glosses used in typological publications. In this format, wordforms are supplied with lemmas and lexical/grammatical categories vertically aligned below each wordform. Lemmas are displayed on the first line with their lexical categories in parentheses. The second line shows the list of inflectional categories in braces. When available, English translations are given in the last line. If the wordform has several possible analyses, these are separated from each other by a gray line.

- KWIC. Key Words In Context is a conventional way of displaying the search results so that matching tokens are visually aligned. KWIC layout is typically used when the output is being sorted by wordform or by left wordform. To get metatext data, click Expand. To see the context of the match, click Expand (shows regular expanded context) or scroll the KWIC screen left or right by clicking the arrows.

|

